在昨天的教學中,我們將 Iris 資料集儲存為 CSV 檔案。今天我們將學習如何在 Google Colab 中讀取這個 CSV 檔案,並進一步操作資料。
有任何問題,都歡迎私訊我的IG
點我私訊
首先,我們需要在昨天創建的 Iris 資料夾中,再新增一個 Google Colab 筆記本,並命名為 iris_input。
在新的筆記本中,我們首先需要匯入 Pandas 套件,這是一個強大的資料處理工具。
import pandas as pd
接下來,我們使用 Pandas 套件來讀取這個 CSV 檔案,並將其載入為 DataFrame。
# 讀取 CSV 檔案
iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
# 查看前幾筆資料
print(iris_df.head())
這段程式碼會將 iris_dataset.csv 讀取並載入為一個 DataFrame,並顯示前幾筆資料。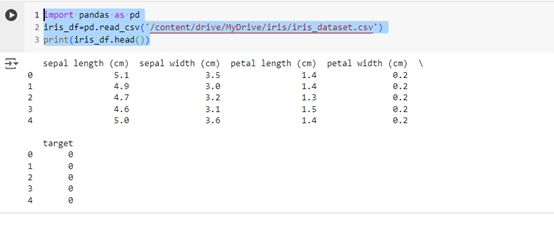
我們可以使用 Pandas 的其他方法來進一步檢視資料的結構和基本資訊,例如查看資料框的形狀、列出欄位名稱,或是顯示每個欄位的數據類型:
# 查看資料的形狀 (行數與列數)
print(iris_df.shape)
# 列出欄位名稱
print(iris_df.columns)
# 顯示每個欄位的數據類型
print(iris_df.dtypes)
這些方法能幫助我們快速了解資料的結構與內容。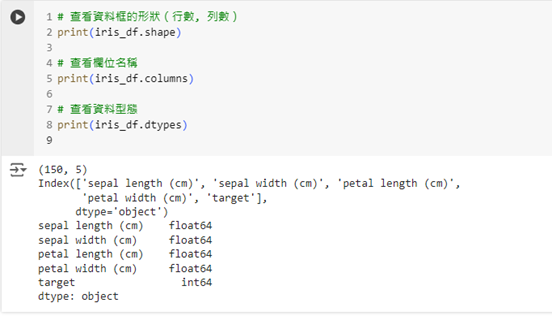
除了顯示前幾筆資料外,我們還可以使用 describe() 來查看資料的統計摘要,幫助我們更深入地理解資料分佈:
# 查看統計摘要
print(iris_df.describe())
這個方法會列出資料的平均值、標準差、最小值、最大值等基本統計資訊。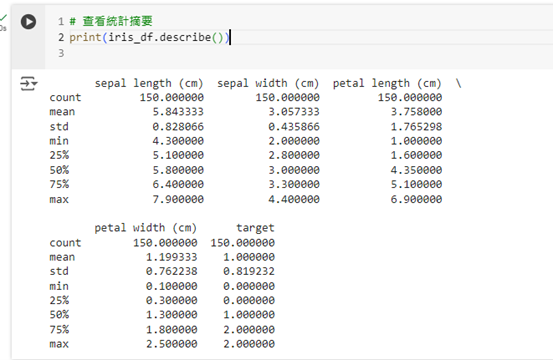
以下是對程式碼 iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv') 的詳細解釋:
pd.read_csv()pd.read_csv() 是 Pandas 套件中用來讀取 CSV(Comma-Separated Values,逗號分隔值)檔案的函數。它可以將一個 CSV 檔案轉換為一個 Pandas 的 DataFrame(資料框),這是一種類似於 Excel 表格的資料結構,非常適合用來處理結構化的表格資料。
pd 是 Pandas 的常用別名,代表 Pandas 模組。這個別名通常是在我們匯入 Pandas 時用 import pandas as pd 所設置的。read_csv() 是 Pandas 中用來讀取 CSV 檔案的函數。'/content/drive/MyDrive/iris/iris_dataset.csv'這是一個字串,代表檔案的路徑,它指向我們要讀取的 CSV 檔案。這個路徑告訴 read_csv() 函數我們的檔案位於 Google Drive 的 Iris 資料夾中。
/content/drive/ 是 Google Colab 中 Google Drive 掛載的根目錄。/MyDrive/iris/ 是 Google Drive 的資料夾路徑,表示這個檔案位於 Google Drive 的主目錄 (MyDrive) 下的 iris 資料夾中。iris_dataset.csv 是我們要讀取的 CSV 檔案的名稱。iris_df這是我們自定義的一個變數名稱,用來儲存從 CSV 檔案中讀取的資料。讀取完成後,iris_df 變數將會是一個 Pandas 的 DataFrame,包含了 iris_dataset.csv 中的所有資料。
iris_df 中的 df 通常代表 DataFrame,這是一個處理表格資料的標準資料結構,它類似於 Excel 中的工作表。DataFrame 能夠輕鬆地進行資料篩選、排序、聚合等操作。這段程式碼的作用是:
pd.read_csv() 函數讀取位於 Google Drive 上的 iris_dataset.csv 檔案。iris_df 這個變數中,並轉換成一個 Pandas 的 DataFrame。iris_df 這個 DataFrame 進行各種資料分析和操作。FileNotFoundError)。iris_dataset.csv 是正確的 CSV 檔案格式,否則 pd.read_csv() 函數可能無法正常讀取資料。今天我們學習了如何在 Google Colab 中讀取 CSV 檔案,並進行一些基本的資料操作。透過這些步驟,我們可以輕鬆讀取並處理本地的 CSV 檔案,進行進一步的分析。
接下來的課程中,我們會深入探討如何進行資料的清理和視覺化。準備好開始進行更深入的資料處理了嗎?


 iThome鐵人賽
iThome鐵人賽